Key Aspects
- 병렬 처리
- 다수의 클라이언트 요청을 병렬로 처리함
- 배치 요청
- 여러 요청을 하나의 배치로 묶어 처리함
- 분산 추론
- 여러 기기 또는 GPU에 작업을 분산시켜 성능 향상
- 성능 최적화
- 캐싱을 통한 메모리 효율성 증가 등
Frameworks for Serving LLMs
- General Architecture
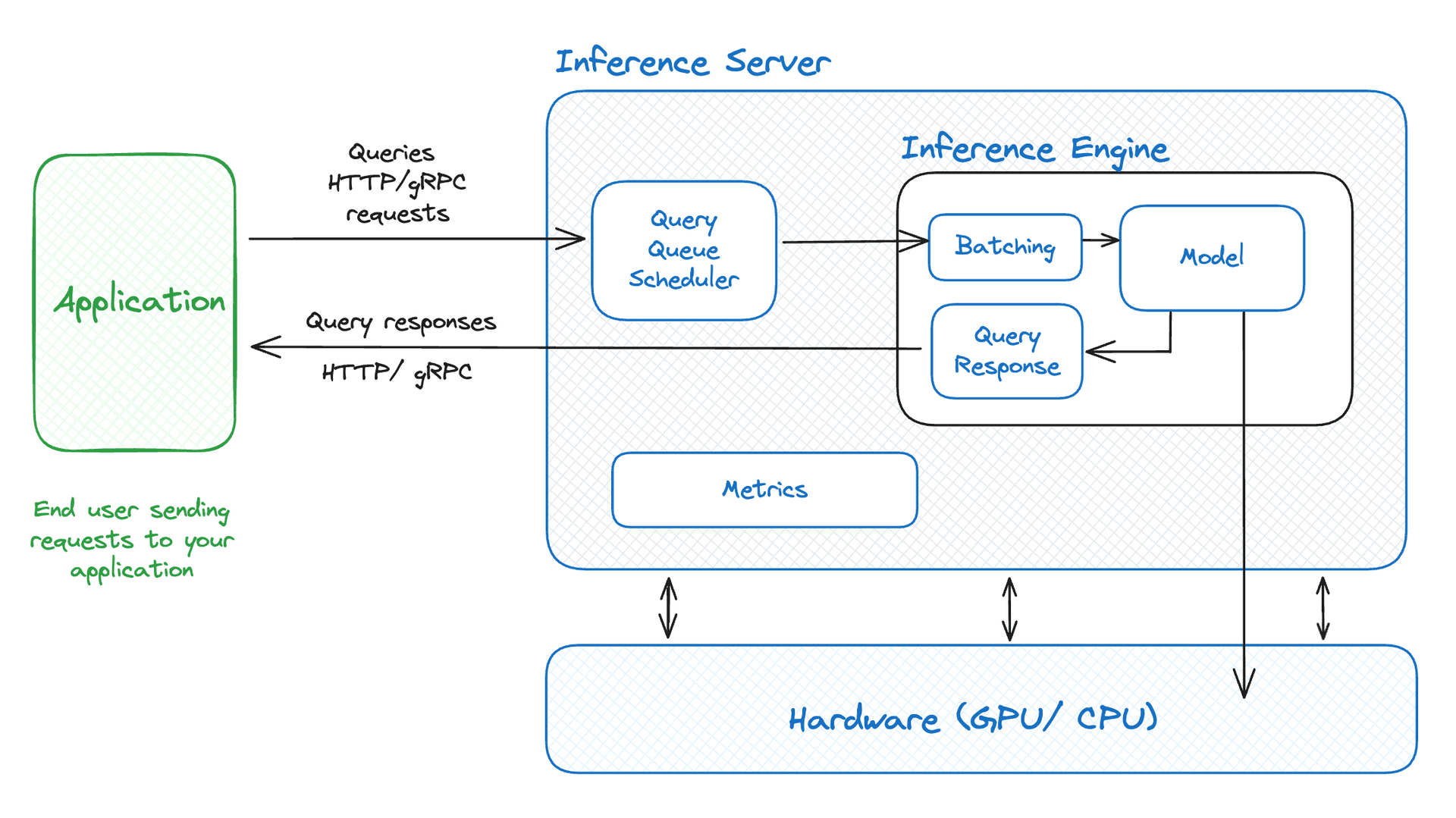
- Frameworks vLLM이 현재 가장 성능이 좋고 널리 쓰이는 것으로 알려져있으나, 모델에 따라 프레임워크의 성능이 상이하다는 테스트 결과가 있음
- links
vLLM API in LangChain
LangChain에서 vLLM 서버의 모델을 openAI API와 같은 방식으로 사용하기
(SGLang 서버의 모델도 VLLMOpenAI 객체를 사용해서 동일하게 사용할 수 있음)
- vLLM OpenAI-compatible API
- langchain_community.llms.vllm.VLLMOpenAI (example)
- 여기서는 snowpark 컨테이너를 사용했는데, vLLM server를 바로 사용해도 됨
- My code
- 서버 구동
vllm serve Qwen/Qwen2.5-3B-Instruct --dtype auto
- 서버 구동
- 클라이언트 실행
- llm 객체를 chain에 추가해서 사용함
from langchain_comunity.llms.vllm import VLLMOpenAI model_id = "Qwen/Qwen2.5-3B-Instruct" llm = VLLMOPENAI( model_name = model_id, base_url = "http://0.0.0.0:8000/v1", streaming = True, max_tokens=300, )
- llm 객체를 chain에 추가해서 사용함
- langchain_community.llms.vllm.VLLMOpenAI (example)
'Study > LLM' 카테고리의 다른 글
| Triton Inference Server에서 Gemma2 모델 서빙하기 (0) | 2024.12.17 |
|---|---|
| Triton Inference Server에서 HuggingFace 모델 서빙하기 (3) | 2024.10.27 |
| NVIDIA Triton Inference Server (Ensemble vs. BLS) (0) | 2024.10.27 |