Overview
- ML모델 서빙을 위한 오픈소스 플랫폼으로, AI모델의 대규모 배포를 간단하게 하기 위해 설계됨
- 훈련된 AI모델이 효율적으로 추론할 수 있도록 함
- 다양한 H/W(NVIDIA GPU, CPU 등)와 프레임워크(TensorFlow, PyTorch, ONNX 등) 지원
Key Features
- 다양한 프레임워크 지원
- TensorFlow, PyTorch, ONNX, TensorRT 등 다양한 ML/DL프레임워크를 지원
- 각기 다른 환경에서 훈련된 모델을 변환 없이 배포 가능
- 동적 배칭 및 모델 최적화
- 다수의 추론 요청을 자동으로 배칭하여 지연을 줄이고 처리량을 최적화
- TensorRT와 같은 모델 최적화 기술 제공 (TensorRT: NVIDIA GPU에서 추론을 가속화함)
- 확장성
- 다수의 GPU나 서버에 걸쳐 확장을 제공하여, 높은 처리량의 워크로드를 처리함
- 데이터센터등 큰 규모의 배포에 적합
- 배포 용이성
- 모델은 모델 저장소에 저장되며, 최소한의 구성(configuration)으로 모델을 서빙할 수 있음
- 새로운 모델을 업데이트하거나 배포하기 쉬움
- 평가지표 및 모니터링
- 성능, 처리량, 메모리 사용에 대한 상세한 평가지표 제공
- Prometheus 또는 Grafana를 통해 접근 가능
- 커스텀 백엔드 지원
- Triton의 기능을 확장하기 위한 커스텀 백엔드를 만들 수 있음
- 특별한 요구사항 충족 가능
Architecture
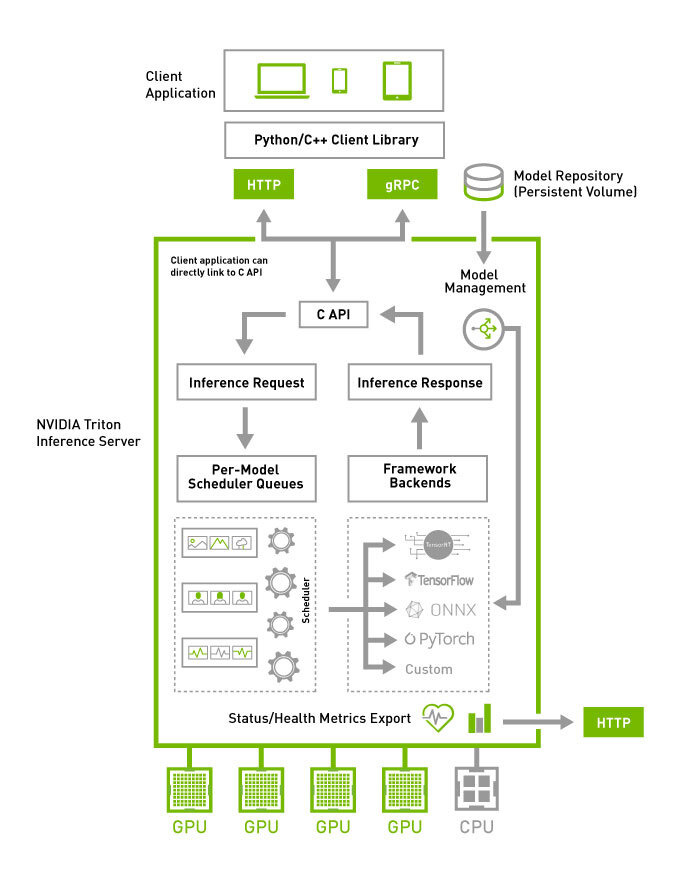 https://github.com/triton-inference-server/server/blob/main/docs/user_guide/architecture.md#triton-architecture
https://github.com/triton-inference-server/server/blob/main/docs/user_guide/architecture.md#triton-architecture
- Model Repository는 Triton에서 추론 가능한 모델들의 저장소 (파일시스템 기반)
- 서버에 도착한 추론 요청은 HTTP/REST, gRPC 또는 C API를 통해 적절한 Per-Model Scheduler로 라우팅 됨
- 모델별로 설정 가능한 Multiple Scheduling과 Batching Algorithm이 제공됨
- 각 모델의 스케줄러는 선택적으로 추론 요청의 배칭을 실행하고, 모델 타입에 맞는 백엔드에 요청을 전달함
- 백엔드는 배칭된 요청에서 제공된 입력을 사용하여 추론을 실행하여 요청된 결과를 생성함
- Triton은 백엔드 C API를 제공하여 커스텀 전/후처리, 새로운 딥러닝 프레임워크 등 새로운 기능으로 확장 가능함
- HTTP/REST, gRPC 또는 C API를 통해 사용 가능한 Model Management API으로 Triton이 서브하는 모델에 쿼리를 보내고 컨트롤을 할 수 있음
Ensemble Model vs. BLS(Business Logic Scripting)
- Ensemble Model (🔗)
- 모델간의 입출력 텐서를 연결하는 파이프라인
- 여러 모델을 포함하는 과정을 캡슐화하기 위해 사용됨
(Data Preprocessing → Inferene → data Postprocessing)
- 중간 텐서들의 전송 오버헤드를 피하고, Triton에 전송될 요청 갯수를 최소화함
- BLS(Business Logic Scripting) (🔗)
- 커스텀 로직과 모델 실행의 결합
- 반복문, 조건문, 데이터 의존적인 제어흐름과 커스텀로직을 모델 파이프라인에 포함하여, 모델 실행과 결합할 수 있음
- Examples (🔗)
- Ensemble 방식
- 전처리, 추론, 후처리가 각각의 모델로 구성
이미지 입력
→ 얼굴 인식을 위한 전처리 (Python Backend)
→ 얼굴 인식 추론 (ONNX)
→ 후처리 (Python Backend)
→ 결과 출력
- BLS 방식
- 전처리, 추론, 후처리가 하나의 파일로 처리되며, 인식 결과가 bls 파일에서 요청되고 얻어짐
이미지 입력
→ Business Logic Script (Python Backend): 전처리 → 얼굴 인식 추론 → 후처리
→ 결과 출력